Crowdsourcing z użyciem Google Docs
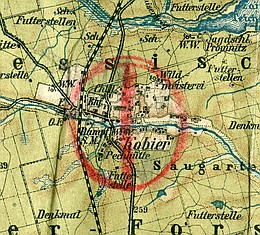
Fragment mapy z okresu Powstań śląskich z archiwów Instutytu Józefa Piłsudskiego, zespół 8 jedn. 164.
Przy pracy nad kolekcją “Powstania Śląskie” w archiwum Instytutu pojawił się dylemat. Archiwa są już zmikrofilmowane a mikrofilmy zeskanowane, ale z ponad 800 jednostek (teczek) udostępnione zostało tylko 50. Wynika to z braku metadanych, szczególnie danych o powstańcach, którzy walczyli w trzech Powstaniach Śląskich w latach 1919-1921. Brak finansowania powodował odsuwanie dokończenia projektu, gdyż nie umieliśmy wykorzystać pomocy wolontariuszy pracujących w domu. Co prawda istniały podobne projekty crowdsourcing, ale były one oparte na specjalnie napisanym oprogramowaniu i sporym finansowaniu projektu.
Wpadliśmy wtedy na pomysł, aby użyć gotowego, publicznie dostępnego systemu. Google Docs (teraz Google Drive) wydawał się być użyteczny dla tego projektu. Wymagało to dopasowania naszych wymagań do możliwości systemu, i narażało nas na wpadkę jeśliby Google w sposób istotny zmienił format dokumentów (co już się raz zdarzyło). Ale postanowiliśmy zaryzykować.
Materiałem źródłowym są skany dokumentów, głownie dużych i mniejszych ksiąg – spisów osobowych powstańców w różnych jednostkach wojskowych. Nasz system opisywania dokumentów archiwalnych oparty jest na DSpace, bardzo szeroko stosowanym otwartym oprogramowaniy do opisu metadanych. Trzeba było więc zbudować system rozproszonej pracy (crowdsourcing) a potem pożenić ze sobą dane zbierane w lokalnie i zdalnie. Wymaganiem podstawowym było to, że system musiał być prosty na tyle, żeby osoby bez specjalnego szkolenia w obsłudze mogły pracować i wprowadzać dobrej jakości dane. Zdecydowaliśmy się na bezpośrenie użycie arkusza kalkulacyjnego, bez specjalnych formularzy wprowadzania danych. Arkusze kalkulacyjne są dość powszechnie stosowanym narzędziem, i liczyliśmy na to, że użytkownik mając wgląd w całość swojego fragmentu pracy będzie mógł łatwo poprawić błędy. Wymaganymi polami były numer jednostki archiwalnej, strona i nazwisko; inne pola były opcjonalne. Jedynym polem zaopatrzonym w walidację było pole daty (z uwzględnieniem możliwości wpisania tylko roku, co nie jest trywialne w polach formatowanych jako data).
Jak jednak dostarczyć widoku skanu? Do tego celu użyliśmy Google+, które pozwala w bardzo granularny sposób udostępniać albumy – kolekcje zdjęć. Zastosowanie programu Picasa do wybierania i umieszczania w ‘chmurze’ albumów odpowiadających jednostkom pozwoliło na uproszczenie całego procesu. Arkusz kalkulacyjny 'Powstancy’, udostępniony pracującym, posiada podstronę zadań, w której przypisane każdemu wolontariuszowi zadanie jest związane z linkiem do albumu w Google+. Brak jednej z podstawowej funkcji, powiększania (niezbędnego do przyjrzenia się szczegółowi ręcznie pisanego tekstu), udało się ominąć przez użycie opcji pobrania obrazu na swój komputer. Wolontariusz ma więc teraz możliwość ustawienia na ekranie obok siebie oryginalnego obrazu i tabelki, do której może wpisywać dane.
Obróbka danych ulegała ewolucji. Zaskoczyła nas liczba chętnych, i szybko okazało się, że jedna tabela nie wystarczy, ze względu na ograniczenia liczby rzędów i kolumn w Google Docs. Trzeba też było dokładnie sprawdzać dane, nie wszyscy wolontariusze zwracali uwagę na dokładnośc pracy. Rozdzieliliśmy więc pracę na kilka tabel, korzystając z świetnej obsługi programowej (API) Google. Funkcje bazodanowe w języku SQL pozwalały na łatwą agregację danych, możliwe też było robienie linków pomiedzy tabelami. Dane surowe, dane w trakcie sprawdzania i dane już gotowe są teraz umieszczone w oddzielnych dokumentach. Dane już sprawdzone są dalej przerabiane w kilku etapach, i udostępniane na stronie Powstań Śląskich. Połaczenia między dokumentami i funkcje powodują, że tabele są ‘żywe’ i w każdej chwili odzwierciedlają postęp prac każdego wolontariusza jak i dane podsumowujące.
Dzięki pomocy przyjaciół Instytutu, którzy rozpropagowali ideę zdalnego wolontariatu, i dzięki pracy i zaangażowaniu Agnieszki Petli (teraz Brissey), która od początku zajmuje się archiwami Powstańców i bardzo cierpliwie szkoli wolontariuszy, organizuje dane, przydziela zadania i sprawdza wyniki ich pracy, projekt crowdsourcing archiwum Powstań Śląskich z użyciem chmury bitowej (cloud computing) spotkał się z dużym sukcesem. Wolontariusze wprowadzili już ponad 50 tysięcy rekordów, które będa sukcesywnie udostępniane. Oczywiście chętnie przyjmujemy dalszych wolontariuszy, bez których projekt nie byłby możliwy.
Marek Zieliński
Artykuł ukazał się 23 czerwca 2012 w Blogu archiwistów i bibliotekarzy Instytutu Piłsudskiego
Może Cię też zainteresować:











 Jednym z najważniejszych zadań systemu zarządzania aktami (RM) jest dokumentowanie działalności instytucji czy organizacji, tworzenie zapisanej i niezmienialnej pamięci jej działalności i historii, zapisywanie dowodów które mogą być użyte (np. przez historyka lub sąd) z pewnością, że nie zostały one zmienione czy zafałszowane. W tym aspekcie MoReq2012 jest istotny również dla archiwów, których funkcja pokrywa się w dużym stopniu z tymi zadaniami.
Jednym z najważniejszych zadań systemu zarządzania aktami (RM) jest dokumentowanie działalności instytucji czy organizacji, tworzenie zapisanej i niezmienialnej pamięci jej działalności i historii, zapisywanie dowodów które mogą być użyte (np. przez historyka lub sąd) z pewnością, że nie zostały one zmienione czy zafałszowane. W tym aspekcie MoReq2012 jest istotny również dla archiwów, których funkcja pokrywa się w dużym stopniu z tymi zadaniami.



.jpg){kind=link}