

 Na niedawnej konferencji METRO (Metropolitan New York Library Council) miała miejsce prezentacja przedstawicieli grupy ‘Humanistyka Cyfrowa w New York City’ (NYCDH). Grupa ta działa od połowy 2011, i zrzesza zainteresowanych Humanistyką Cyfrową z Nowego Jorku i okolic. Dostarcza ona forum wielu różnym organizacjom i małym grupom osób które pracują nad jakimiś problemami związanymi z humanistyką cyfrową. Uczelnie, w których pracują członkowie komisji sterującej grupy (takie jak NYU, CUNY, Columbia, Pratt i inne) udzielają miejsca na spotkania. Kalendarz grupy jest pełny, często jest kilka wydarzeń lub spotkań w tygodniu. Grupa jest otwarta, i po zarejestrowaniu się każdy członek może wpisać w kalendarz imprezę jaka organizuje i wziąć udział w już ogłoszonej.
Na niedawnej konferencji METRO (Metropolitan New York Library Council) miała miejsce prezentacja przedstawicieli grupy ‘Humanistyka Cyfrowa w New York City’ (NYCDH). Grupa ta działa od połowy 2011, i zrzesza zainteresowanych Humanistyką Cyfrową z Nowego Jorku i okolic. Dostarcza ona forum wielu różnym organizacjom i małym grupom osób które pracują nad jakimiś problemami związanymi z humanistyką cyfrową. Uczelnie, w których pracują członkowie komisji sterującej grupy (takie jak NYU, CUNY, Columbia, Pratt i inne) udzielają miejsca na spotkania. Kalendarz grupy jest pełny, często jest kilka wydarzeń lub spotkań w tygodniu. Grupa jest otwarta, i po zarejestrowaniu się każdy członek może wpisać w kalendarz imprezę jaka organizuje i wziąć udział w już ogłoszonej.
Na stronie NYCDH można znaleźć grupy dyskusyjne o wielu tematach takich jak “Pedagogika Cyfrowa”, “Grupa OMEKA”, “Bibliotekarze w Humanistyce Cyfrowej”, “Grupa analizy tekstu”, “Grupa eksperymentów cyfrowych”, “Antyki i techniki cyfrowe” i inne. Planowane na najbliższy okres i niedawno zakończone imprezy dobrze obrazują działalność grupy.
Własność intelektualna w naukach humanistycznych – panel dyskusyjny z udziałem administratora uczelni, prawnika, bibliotekarza i studenta o napięciach pomiędzy egzekwowaniem praw a uczelnianą tradycją otwartego zdobywania wiedzy.
Muzeum po-cyfrowe – wykład Ross Perry z University of Leicester.






 Kiedy oglądamy stare zdjęcie, na odwrocie często możemy znaleźć stempelek fotografa, notatkę na temat miejsca i daty zdjęcia, a nawet kto na nim jest. Ale gdzie jest “odwrotna strona” zdjęcia cyfrowego?
Kiedy oglądamy stare zdjęcie, na odwrocie często możemy znaleźć stempelek fotografa, notatkę na temat miejsca i daty zdjęcia, a nawet kto na nim jest. Ale gdzie jest “odwrotna strona” zdjęcia cyfrowego?
 EAD (Encoded Archival Description) jest standardem stworzonym specjalnie w celu zakodowania pomocy archiwalnych. Z tego powodu jest on pewnego rodzaju hybrydą. Z jednej strony stara się odzwierciedlić sposób, w jaki pracują archiwiści tworząc pomoce archiwalne, z drugiej stara się wprowadzić dyscyplinę i dokładność niezbędną do elektronicznej obróbki dokumentu. W wyniku mamy sporo dowolności w umiejscowieniu danych, co ułatwia pracę archiwiście a jednocześnie utrudnia wymianę danych. W nowej wersji EAD (EAD3), która jest w przygotowaniu od kilku lat, spodziewane jest zmniejszenie tych dowolności.
EAD (Encoded Archival Description) jest standardem stworzonym specjalnie w celu zakodowania pomocy archiwalnych. Z tego powodu jest on pewnego rodzaju hybrydą. Z jednej strony stara się odzwierciedlić sposób, w jaki pracują archiwiści tworząc pomoce archiwalne, z drugiej stara się wprowadzić dyscyplinę i dokładność niezbędną do elektronicznej obróbki dokumentu. W wyniku mamy sporo dowolności w umiejscowieniu danych, co ułatwia pracę archiwiście a jednocześnie utrudnia wymianę danych. W nowej wersji EAD (EAD3), która jest w przygotowaniu od kilku lat, spodziewane jest zmniejszenie tych dowolności.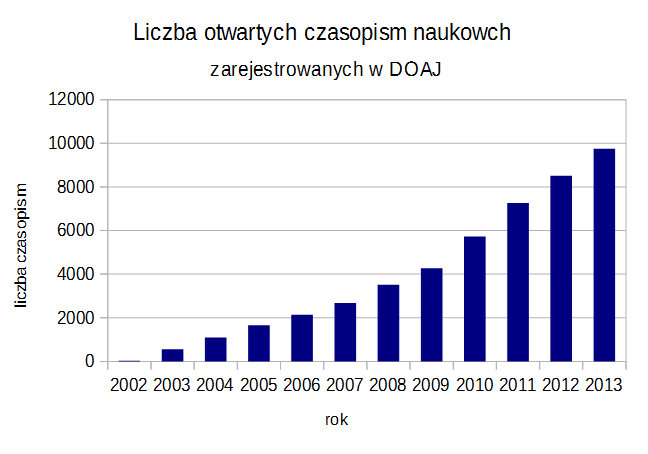
{kind=link}