
Wizualizacja spuścizny kulturowej: otwarte Linked Data w Carnegie Hall cz. 2
Przedstawiamy drugą część gościnnego blogu Roberta Hudsona, archiwisty z Carnegie Hall w Nowym Jorku. W drugim odcinku Rob opowiada o wynikach swojej pracy nad przekształceniem bazy danych Carnegie Hall w postac otwartego Linked Data. Po dokonaniu konwersji i uzyskaniu ok miliona „trójek” RDF, pora na dotarcie do narzędzi pozwalających na wizualizację i przeglądanie danych. Blog jest ilustorowany nagraniami pokazującymi na żywo eksploracje danych, z komentarzem autora.
Part II: Product
 In Part I of this blog, I began telling you about my experience transforming Carnegie Hall’s historical performance history data into Linked Open Data, and in addition to giving some background on my project and the data I’m working with, I talked about process: modeling the data; how I went about choosing (and ultimately deciding to mint my own) URIs; finding vocabularies, or predicates, to describe the relationships in the data; and I gave some examples of the links I created to external datasets.
In Part I of this blog, I began telling you about my experience transforming Carnegie Hall’s historical performance history data into Linked Open Data, and in addition to giving some background on my project and the data I’m working with, I talked about process: modeling the data; how I went about choosing (and ultimately deciding to mint my own) URIs; finding vocabularies, or predicates, to describe the relationships in the data; and I gave some examples of the links I created to external datasets.
In this installment, I’d like to talk about product: the solutions I examined for serving up my newly-created RDF data, and some useful new tools that help bring the exploration of the web of linked data down out of the realm of developers and into the hands of ordinary users. I think it’s noteworthy that none of the tools I’m going to tell you about existed when I embarked upon my project a little more than two years ago!
As I’ve mentioned, my project is still a prototype, intended to be a proof-of-concept that I could use to convince Carnegie Hall that it would be worth the time to develop and publish its performance history data as Linked Open Data (LOD) — at this point, it exists only on my laptop. I needed to find some way to manage and serve up my RDF files, enough to provide some demonstrations of the possibilities that having our data expressed this way could afford the institution. I began to realize that without access to my own server this would be difficult. Luckily for me, 2014 saw the first full release of a linked data platform called Apache Marmotta by the Apache Software Foundation. Marmotta is a fully-functioning read-write linked data server, which would allow me to import all of my RDF triples, with a SPARQL module for querying the data. Best of all, for me, was the fact that Marmotta could function as a local, stand-alone installation on my laptop — no web server needed; I could act as my own, non-public web server. Marmotta is out-of-the-box, ready-to-go, and easy to install — I had it up and running in a few hours.
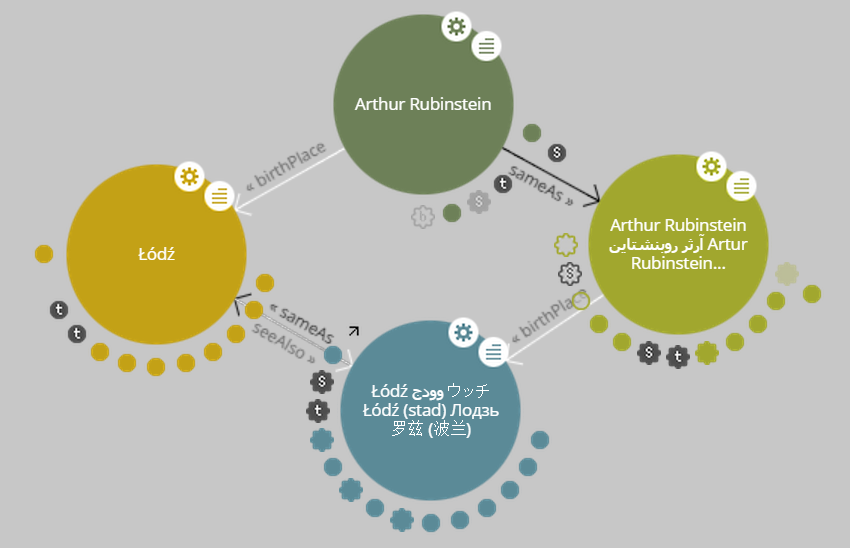
In addition to giving me the capability to serve up, query, and edit my RDF data, Marmotta has some great built-in visualization features. The screencast below demonstrates one of the map functions, with which I can make use of the GeoNames URIs I’ve used in my dataset to identify the birthplaces of composers and performers.
Czytaj dalej „Visualizing Cultural Heritage: Linked Open Data and the Carnegie Hall Archives p. 2”