

 Niedawno (w tygodniu 13-18 stycznia 2014) Electronic Frontier Foundation (EFF) zorganizowała “Tydzień praw autorskich”, aby przypomnieć nam, jak złożony jest to problem oraz co możemy i powinniśmy zrobić w sprawie praw autorskich. Dla każdego z sześciu tematów (po jednym na dzień), uczestniczące instytucje wniosły swój wkład w postaci blogów, artykułów i innych inicjatyw. Jest to fascynująca lektura, z którą warto się zapoznać. Poniżej krótkie omówienie zilustrowane cytatami z wybranych tekstów:
Niedawno (w tygodniu 13-18 stycznia 2014) Electronic Frontier Foundation (EFF) zorganizowała “Tydzień praw autorskich”, aby przypomnieć nam, jak złożony jest to problem oraz co możemy i powinniśmy zrobić w sprawie praw autorskich. Dla każdego z sześciu tematów (po jednym na dzień), uczestniczące instytucje wniosły swój wkład w postaci blogów, artykułów i innych inicjatyw. Jest to fascynująca lektura, z którą warto się zapoznać. Poniżej krótkie omówienie zilustrowane cytatami z wybranych tekstów:
Autor: Marek Zieliński
Standardy metadanych: Dublin Core
Przy opisie jakiegoś zasobu – książki, kolekcji medali, dokumentu, obrazu – mamy w zasadzie dwie możliwości. Dokonać opisu w postaci narracji (zwykle sięgamy do tego, co jest pod ręką, czyli w dobie komputerów po procesor tekstu). Albo dokonać opisu w postaci struktury – na przykład w tabeli arkusza rozliczeniowego. Opis w postaci narracji pozwala na pełna ekspresję intencji badacza, i jednocześnie prawie uniemożliwia dalsza automatyczną przeróbkę danych. W Instytucie Piłsudskiego mamy doskonale zrobiony przez doświadczonego fachowca opis kolekcji falerystycznej, który ma postac narracji. Poszczególne elementy opisu (nazwa odznaki, jej twórca, miejsce stworzenia, daty itp.) są graficznie uwydatnione- np przez użycie czcionki wytłuszczonej, kursywy, przez oddzielanie elementów przecinkami, średnikami itp. Jednocześnie, jeśli jakiejś informacji brak, po przecinku znajdzie się już inny element opisu. Setki stron takiego tekstu wymagają wielu dni a nawet tygodni pracy aby zrobić prostą tabelkę którą można wyświetlić na stronie internetowej, gdyż zautomatyzowanie konwersji jest prawie niemożliwe.
Nawet prosta tabela w arkuszu rozliczeniowym daje strukturę – tytuł bedzie zawsze np. w kolumnie trzciej a data w siódmej itp. Jeśli więc użyliśmy jakiejś struktury, i nie mieszalismy np. miejsca z datą, mamy podstawy do użycia danych w różny sposób, taki, jakiego w danym momencie potrzebuje projektant wystawy, witryny internetowej czy inwentarza. Przy użyciu standardów metadanych najważniejszą decyzją jest użycie struktury adekwatnej do opisywanego zasobu. Przetłumaczenie tej struktury na taki czy inny standard metadanych jest wtedy zajęciem trywialnym. Mówiąc trywialnym mam na myśli to, że da się zautomatyzować – kiedy raz stworzymy algorytm konwersji, przeróbka 100 czy 100 tysięcy rekordów to tylko sprawa zapuszczenia komputera na sekundy albo godziny pracy.
Doroczna konferencja METRO 2014
 W środę, 15 stycznia 2014 odbyła się w Nowym Jorku doroczna konferencja Metropolitan New York Library Council (METRO). Konferencja, która miała miejsce w nowoczesnym budynku Baruch College (CUNY), zgromadziła ponad dwustu przedstawicieli bibliotek archiwów, uczelni i innych instytucji z Nowego Jorku i okolic. Uczestnicy mieli do wyboru 25 prezentacji i wykładów przedstawiających różne aspekty pracy, możliwości i osiągnięć szeroko rozumianego środowiska bibliotekarskiego. Do przyjętych do prezentacji projektów zakwalifikował się referat przedstawicieli Instytutu Piłsudskiego: Dr Marka Zielińskiego i Dr Iwony Korga p.t. Digitization of Polish History 1918-1923 opisujący projekt digitalizacji i przedstawiający wybrane materiały, technikę opracowania danych, prezentację online i wykorzystanie danych przez Internautów.
W środę, 15 stycznia 2014 odbyła się w Nowym Jorku doroczna konferencja Metropolitan New York Library Council (METRO). Konferencja, która miała miejsce w nowoczesnym budynku Baruch College (CUNY), zgromadziła ponad dwustu przedstawicieli bibliotek archiwów, uczelni i innych instytucji z Nowego Jorku i okolic. Uczestnicy mieli do wyboru 25 prezentacji i wykładów przedstawiających różne aspekty pracy, możliwości i osiągnięć szeroko rozumianego środowiska bibliotekarskiego. Do przyjętych do prezentacji projektów zakwalifikował się referat przedstawicieli Instytutu Piłsudskiego: Dr Marka Zielińskiego i Dr Iwony Korga p.t. Digitization of Polish History 1918-1923 opisujący projekt digitalizacji i przedstawiający wybrane materiały, technikę opracowania danych, prezentację online i wykorzystanie danych przez Internautów.
Konferencja rozpoczęła się od wykładu znanej w środowisku amerykańskim bibliotekarki i blogerki Jessamyn West, która w wykładzie p.t. Open, Now! opowiedziała o możliwościach otwartego dostępu (open access) dającego nieskrępowany, bezpłatny dostęp do szeroko rozumianej informacji internetowej. Mówiła o projektach Google, Digital Public Library of America i o problemach prawnych związanych z takim dostępem.
Projekty digitalizacji


“A ona sama różaną barwą na twarzy rozlaną i wdzięcznymi a jasnymi oczyma serce swe smutne i zbytnią bojaźnią ściśnione pokrywała.” – Ksiega Estery z Codex Sinaiaticus 4:17m – 5:2 – ks. 9 rozdz. 5
Odpowiedzi na pytanie “Czym jest digitalizacja?” są tak różnorodne, jak różne są zasoby które są zamieniane w postać elektroniczną i jak różne są instytucje, które podejmują się tego zadania. Istnieją projekty, które zajmują się tylko jednym dokumentem, inne opisują z dużą szczegółowością jakieś wydarzenie lub twórczość jednej osoby, jeszcze inne dostarczają dostępu do wirtualnego archiwum historii. Są projekty które wykazują się nowatorskimi rozwiązaniami technicznymi, połączeniem różnych technik i źródeł informacji, sposobami odszukania i przeglądania zasobów. Instytucje posiadające bogate zbiory opracowują wystawy wybranych kolekcji, podczas gdy inne opierają się na współpracy wielu instytucji aby pokazać wspólnie jeden zasób. Oto garść przykładów ilustrujących tę różnorodność:
Codex Sinaiaticus to powstały w połowie czwartego wieku manuskrypt zawierający tekst Biblii po grecku, z najstarszą kompletną kopią Nowego Testamentu. Do połowy 19 wieku manuskrypt ten był przechowywany w klasztorze Świętej Katarzyny, najstarszym istniejącym dziś klasztorze chrześcijańskim, położonym u stóp góry Synaj (Góry Mojżesza) w Egipcie. Dziś fragmenty tego rękopisu znajdują się w czterech instytucjach: oprócz Klasztoru Świętej Katarzyny także w Bibliotece Brytyjskiej w Londynie, Bibliotece Uniwersytetu w Lipsku i w Rosyjskiej Narodowej Bibliotece w Petersburgu. Strona powstała jako wynik współpracy tych czterech instytucji. Jest nadzwyczaj starannie opracowana i zawiera wszystkie arkusze i ocalałe fragmenty kodeksu. Oprócz skanu oryginału strony podana jest transkrypcja w języku greckim, a dla niektórych stron również tłumaczenie na inne języki (angielski, niemiecki, rosyjski). Linki umożliwiają zlokalizowanie transkrypcji fragmentów tekstu po kliknięciu w oryginał.
Wstęp do Linked Data
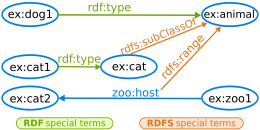
|
Przykład schematu RDF Linked Data (reifikacja) – autor Karima Rafes (własne dzieło) [CC-BY-SA-3.0], via Wikimedia Commons) |

Linked Data to mechanizm którym posługuje się Semantic Web albo “Web 3.0 w budowie”. Te powiązane ze sobą określenia są tak nowe, że nie maja jeszcze ‘oficjalnego’ polskiego tłumaczenia. Na czym polega Semantic Web? Wszyscy używamy World Wide Web (www). Podstawowym składnikiem www sa tak zwane hiperłącza (hiperlink), odnośniki albo odsyłacze do innych stron, źródeł informacji. Kliknięcie w taki odsyłacz (ma w nazwie http) powoduje otwarcie w przeglądarce internetowej nowej strony pozwalającej na rozszerzenie naszej wiedzy lub dalsze zaspokojenie ciekawości. Www została stworzona dla naszej konsumpcji, i jak język naturalny, jest rozumiana przez ludzi.
Jak pisałem poprzednio, komputery są w porównaniu z nami bardzo mało rozgarnięte. Trzeba im wszystko przedstawiać kawa na ławę, metodą łopatologiczną. Ale są za to bardzo szybkie, a przede wszystkim potrafią ogarnąć o wiele więcej danych na raz niż my. A to znaczy, że odszukają w petabajtach informacji to, czego właśnie potrzebujemy. Aby to było możliwe, musimy być dużo bardziej precyzyjni, mieć wiarygodne źródła informacji i system który to wszystko połączy. Tym systemem jest właśnie Linked Data.
Digitalizacja a cyfryzacja


Digitalizacja. Ilustracja wykonana z wykorzystaniem pracy Junior Melo udotępnionej przez Wikimedia Commons [CC-BY-SA-3.0])
W języku polskim pojawiło się nowe słowo, ‘cyfryzacja’. Zostało ono spopularyzowane przez stworzenie w 2011 roku nowego ministerstwa Administracji i Cyfryzacji, obejmującego szeroki zakres działania, od mniejszości religijnych do informatyzacji. Słowo to zwiększyło tylko pogmatwanie, gdyż niektórzy zaczęli używać go zamiast słowa digitalizacja, które także jest używane w różnych znaczeniach. Czym więc jest digitalizacja, formatowanie cyfrowe i cyfryzacja?
Formatowanie cyfrowe
To, co dociera do naszych zmysłów ma najczęściej charakter sygnału ciągłego, t.j. takiego, który może przyjmować dowolne wartości w swojej domenie. Światło – zarówno w jego natężeniu jak i kolorze jest sygnałem ciągłym, takim jest też dźwięk (charakteryzujący się też natężeniem i tonem). Natomiast nuty albo tekst zapisany na papierze jest ciągiem dyskretnym, tj. ciągiem znaków, z których każdy jest wybrany z tylko ograniczonego zestawu możliwości.
Konferencje naukowe polonii
Każdego roku odbywają się konferencje organizowane przez środowiska polonijne na świecie. W tym roku członkowie Rady Instytutu Piłsudskiego wzięły udział w trzech konferencjach naukowych które odbyły się na terenie Stanów Zjednoczonych i Europy.
W dniach 15-16 maja 2013 miała miejsce konferencja i spotkanie naukowe Polish-American Historical Association (PAHA). Konferencja odbyła się w University at Buffalo, The State University of New York. PAHA jest organizacją pożytku publicznego która skupia naukowców zajmujących się badaniami nad Polonią. Powstała w roku 1942 jako część Polskiego Instytutu Naukowego, od 1948 jest niezależnym towarzystwem naukowym.
W dniach 14-15 czerwca 2013 odbyła się się konferencja prezentująca badania naukowe Polaków w Ameryce w wielu dyscyplinach nauki. Konferencja jest organizowana corocznie przez Polski Instytut Naukowy w Ameryce (Polish Institute of Arts and Sciences of America – PIASA) i miała miejsce Waszyngtonie. PIASA powstała w 1942 r. początkowo jako kontynuacja na czas okupacji Polskiej Akademii Umiejetnosci w Krakowie a od lat powojennych jako niezależna organizacja. PIASA skupia polsko-amerykańskich uczonych, posiada bibliotekę i archiwum oraz galerię sztuki.
Jak każdego roku odbyła się także Stała Konferencja Muzeów, Archiwów i Bibliotek Polskich na Zachodzie (MAB), w której biorą udział przedstawiciele instytucji polskich działających w Europie Zachodniej i w obu Amerykach. Kolejne spotkanie MAB miało miejsce we wrześniu 2013 r. w Budapeszcie. Podczas konferencji przedstawione zostały referaty dotyczące 150 Rocznicy Powstania Styczniowego i historii polsko-węgierskiej.
Iwona Korga
Artykuł ukazał się 2 kwietnia 2013 w Blogu archiwistów i bibliotekarzy Instytutu Piłsudskiego.
Iwona Drag Korga jest dyrektorem wykonawczym Instytutu Pilsudskiego w Ameryce, absolwentką Uniwersytetu Pedagogicznego w Krakowie i Queens College w Nowym Jorku. Doktor nauk humanistycznych, archiwsta i historyk, pasjonuje sie historia najnowsza, kolekcjami archiwalnymi i edukacją mlodego pokolenia Polonii
Digital Humanities
Poniższy tekst proszę potraktować jako zachętę i wstęp do lektury zbioru esejów Debates in the Digital Humanities pod redakcją Matthew K. Golda, wydanego w 2012 przez University of Minnesota Press. Antologia ta została także opublikowana w nieco rozszerzonej formie jako tekst „open access”, który dostępny jest tutaj.
Digital humanities (w skrócie DH), czy też humanistyka cyfrowa jest relatywnie nową dziedziną, która zdobywa coraz większą popularność w świecie akademickim. Artykuł w angielskiej Wikipedii podaje bardzo zgrabną definicję DH, do której odsyłam zainteresowanych. W skrócie, humanistyka cyfrowa, jest obszarem badań, nauczania i tworzenia łączącego technologie informatyczne i dyscypliny humanistyczne. Obejmuje ona działalność od kuracji kolekcji cyfrowych w sieci po eksplorację danych dokonywaną na wielkich zbiorach. DH stara się połączyć warsztat tradycyjnych dyscyplin humanistycznych (takich jak historia, filozofia, językoznastwo, nauka o literaturze, sztuce, muzyce, itd.) z narzędziami informatycznymi takimi jak wizualizacja danych, pozyskiwanie danych, eksploracja danych i tekstu, statystyka czy publikacja elektroniczna.
Koperty na zdjęcia cyfrowe

 W coraz większym tempie przestawiamy się na fotografię cyfrową. To, co było kilkanaście lat temu nowinką staje się standardem, a aparaty na film staja się rzadkością. Możliwość natychmiastowego sprawdzenia wyniku, powszechność zapisu obrazu w telefonach, tabletach, coraz tańsza pamięć cyfrowa i sprzęt fotograficzny powoduje, że robimy teraz o wiele więcej zdjęć. Jednocześnie jednak fotografia stała się czymś bardzo przejściowym. Kiedyś wklejało się zdjęcia do albumów, kolekcjonowało w pudełkach, dziś siedzą one jako pliki na dysku komputera, a gdy dysk padnie (wszystkie dyski to czeka), nagle tracimy nasze zasoby. Pisałem już wcześniej o osobistych archiwach cyfrowych, tym razem bardziej szczegółowo o tym, jak zapakować i przechować obraz cyfrowy.
W coraz większym tempie przestawiamy się na fotografię cyfrową. To, co było kilkanaście lat temu nowinką staje się standardem, a aparaty na film staja się rzadkością. Możliwość natychmiastowego sprawdzenia wyniku, powszechność zapisu obrazu w telefonach, tabletach, coraz tańsza pamięć cyfrowa i sprzęt fotograficzny powoduje, że robimy teraz o wiele więcej zdjęć. Jednocześnie jednak fotografia stała się czymś bardzo przejściowym. Kiedyś wklejało się zdjęcia do albumów, kolekcjonowało w pudełkach, dziś siedzą one jako pliki na dysku komputera, a gdy dysk padnie (wszystkie dyski to czeka), nagle tracimy nasze zasoby. Pisałem już wcześniej o osobistych archiwach cyfrowych, tym razem bardziej szczegółowo o tym, jak zapakować i przechować obraz cyfrowy.
Zapis obrazu to nie tylko zdjęcia. Skany dokumentów w archiwum to także zapis cyfrowy, który powinien wiernie odzwierciedlać oryginalny dokument. Jak wybrać najlepszy format i sposób zapisu tak, aby przetrwał dla następnego pokolenia, aby nasze wnuki mogły oglądać albumy dziadków, a archiwa przechowały bezcenne już (bo papier się rozpadł) obrazy archiwaliów? Zapisany obraz przechowujemy w opakowaniu zwanym plikiem (file). W dalszym ciągu będzie o formatach tych kopert, do których wkładamy zdjęcia – plików komputerowych, kompresji i metadanych a także przekładaniu obrazu z jednej koperty do innej (konwersji).
Wstęp do standardów metadanych
{kind=link}
Przy omawianiu zderzenia nauk bibliotecznych, archiwistycznych itp. z komputeryzacją i Internetem, centralne miejsce zajmują metadane i sposób ich wyrażania. Metadane to dane o danych, opisy, wyciągi, oznakowania, indeksy, katalogi itp. Ten artykuł jest wstępem do dyskusji i omówienia różnych aspektów metadanych i ich zastosowań.
Dlaczego w ogóle potrzebne są nam metadane? Najprostszą odpowiedzią jest “dlatego, że komputery są raczej nierozgarnięte”. Niech nas nie zmyli fakt, że umieją grać w szachy lepiej od ludzi – to jest zadanie względnie proste w porównaniem ze zrozumieniem języka naturalnego. Ale mimo tego, że są nierozgarnięte, komputery są w stanie przetworzyć dużo więcej informacji w dużo krótszym czasie niż mózg człowieka, więc jest w naszym interesie tłumaczyć zdania języka naturalnego na język zrozumiały przez komputery.